文:林誠夏(Lucien Cheng-hsia Lin),CC-BY-SA-3.0-TW+。
本文標題若要更具體表述,應該是「是否可以合法取用他人以 CC 授權條款發布之資料與素材,用於生成式 AI 模型的訓練?而訓練完成後的模型及其輸出,是否仍受原 CC 授權條款的拘束?若可取用,使用上的界線為何?若不可,又會涉及哪些法律風險?」
若採極短版的模式來回應前述提問:
- 原則上是可以的。從著作授權的角度,使用依 CC 授權釋出的素材來進行 AI 訓練,在法律上通常是被允許的。
- 但訓練後的產出是否仍受原 CC 授權條款拘束,關鍵在於原著作表達是否仍具體呈現。若是,其對應的 BY(姓名標示)、SA(相同方式分享)、NC(非商業使用)、ND(禁止改作)元素皆可能產生效力。
- 除非使用情境僅涉及探勘事實資訊(Text and Data Mining, TDM)或可主張合理使用且成功抗辯,否則仍須遵守 CC 授權條款所附帶的義務與限制。
【CC 授權本身即含「重製、散布及公開演播」之授權】
在實務上,AI 訓練的首要關卡是「是否具備合法重製他人著作的授權基礎」。雖然現代著作權制度涵蓋多元使用態樣(如重製、散布、出租、改作、公開口述、公開播送、公開上映、公開演出、公開傳輸、公開展示),然要合法取得他人著作用於 AI 訓練,首要的核心被授權地位,仍然是素材是否可合法「重製」與「公開利用」。近年來涉及生成式AI 著作侵權的訴訟,依 chatgptiseatingtheworld.com 所整理列表所示 (https://chatgptiseatingtheworld.com/2025/06/30/updated-map-of-us-copyirght-suits-v-ai-jun-30-2025/),相關核心爭議之一,也確實就在取用他人素材時,能否取得合法重製的允許。
2025 年 6 月發布中間裁判的 Bartz v. Anthropic 一案恰為明例,美國加州北區聯邦地方法院法官 William Alsup 裁判 Anthropic 取用他人素材進行AI訓練,就AI訓練成果與輸出應用認定屬於「轉化目的性質的合理使用 (transformative fair use)」,然亦指出 Anthropic 在進行 AI 訓練之時,確實下載並保留了超過七百萬本未經授權的盜版書籍,這是侵犯了原作者著作財產權裡的重製地位,並不屬於合理使用,就此部份將繼續進行庭審,以釐清賠償金額。同年同月於我國科技法律新創圈,引發軒然大波的法源資訊訴七法公司 (Lawsnote)的「臺灣新北地方法院 111 年度智訴字第 8 號判決 (https://www.judicial.gov.tw/tw/cp-1888-1350821-0ca41-1.html)」一審宣判,其中的爭議要點之一,亦在於承審法官認定七法公司擅以爬蟲捉取「重製」之方式侵害他人之著作財產權。
然在開放資料和CC授權領域,並不會產生這樣的問題。事實上所有的 CC授權素材,原權利人皆提供後手利用者得合法重製、散布,以及包括公開播送、公開傳輸及其他各式公開行為之「公開演播」態樣的授權,而論以開放資料,只要該資料是採 OKFN 認定符合開放知識定義之授權條款 (Open Definition Conformant Licenses) 進行發布,原權利人僅得要求後手使用者,必須註引出處或要求相同授權方式分享,其他著作權上的授權允許,則皆是提供給後手的,例如我國訂立符合 Open Definition 的「政府資料開放授權條款-第1版 (OGDL-Taiwan-1.0)」,就明確將「重製、散布、公開傳輸、公開播送、公開口述、公開上映、公開演出、編輯、改作,以及開發各種產品或服務型態衍生物」的地位都提供給使用者。
【訓練成果與輸出是否受 CC 授權條款約束、視原著表達是否仍明確存續而定】
那麼,CC授權的素材可以用於 AI 訓練,但練完 AI 後產出的成果(例如 AI 模型),還有相關成果輸出的客體(例如以 AI 模型再用於生圖或生文章),是否還受訓練素材採用的 CC授權限制或拘束? Creative Commons 於 2023 年底,由當時的首席法律顧問 Kat Walsh 將相關分析表述於「認識 CC 授權與生成式 AI (Understanding CC Licenses and Generative AI)」這篇專論:https://creativecommons.org/2023/08/18/understanding-cc-licenses-and-generative-ai/ ,其後再經接任的 Sarah Pearson,整理於「了解 CC 授權條款與 AI 訓練:法律入門指南」這份文件:https://creativecommons.org/2025/05/15/understanding-cc-licenses-and-ai-training-a-legal-primer/ 。
依據這二篇文件及其相應的輔佐讀物,繪製出如下所示的「AI 與 CC授權流程圖」,要正確解讀該流程圖,閱覽者必須掌控以下幾個要點。
- CC授權是輔助著作權利人採預先授權方式,加速其作品的分享與流通的互惠機制。所以 CC授權機制並不會就各國著作權法未加規範之處,施以更嚴格的使用限制。也就是說,若是各國法制裡,已設有資料探勘 (TDM) 或各類合理使用類型的法律允許,則該等 AI 訓練事務,本不需要得到原素材作者的著作授權,亦即亦不需要獲得相應的 CC授權。
- 採用 AI 訓練方式「學習」他人著作,是否構成對原素材著作表達的承襲是複雜的,並不是非黑即白,也有賴個案和輸出成果的驗證。若是不涉及原著作表達的承襲,亦即不涉及著作權之重製、改作與原作的公開演播,僅是學習原作內嵌的事實資訊,則此等利用情境非屬著作權所限制或保護的範疇,亦不會被 CC授權條款擴張拘束。
- 然當 AI 訓練之後的應用情境涉及商業營利時,則為避免擴大使用爭議或風險,一般來說並不建議取用 CC-BY-NC 或 CC-BY-NC-SA 等帶有「非商業性-NC」元素之素材,來進行 AI 訓練。這是因為 CC-NC 元素於法律條款裡,已明定相關被授權地位之實施「僅限於非商業性目的 (for NonCommercial purposes only)」之利用,解釋起來包括取得 CC-NC 素材的前階段重製行為,亦為被授權地位實施 (to exercise the Licensed Rights) 之一環,等同使用者必須承諾重製該素材之後的各式利用方式,也必須建立在非主要為了或直接關於商業利益或金錢報酬的前提下。
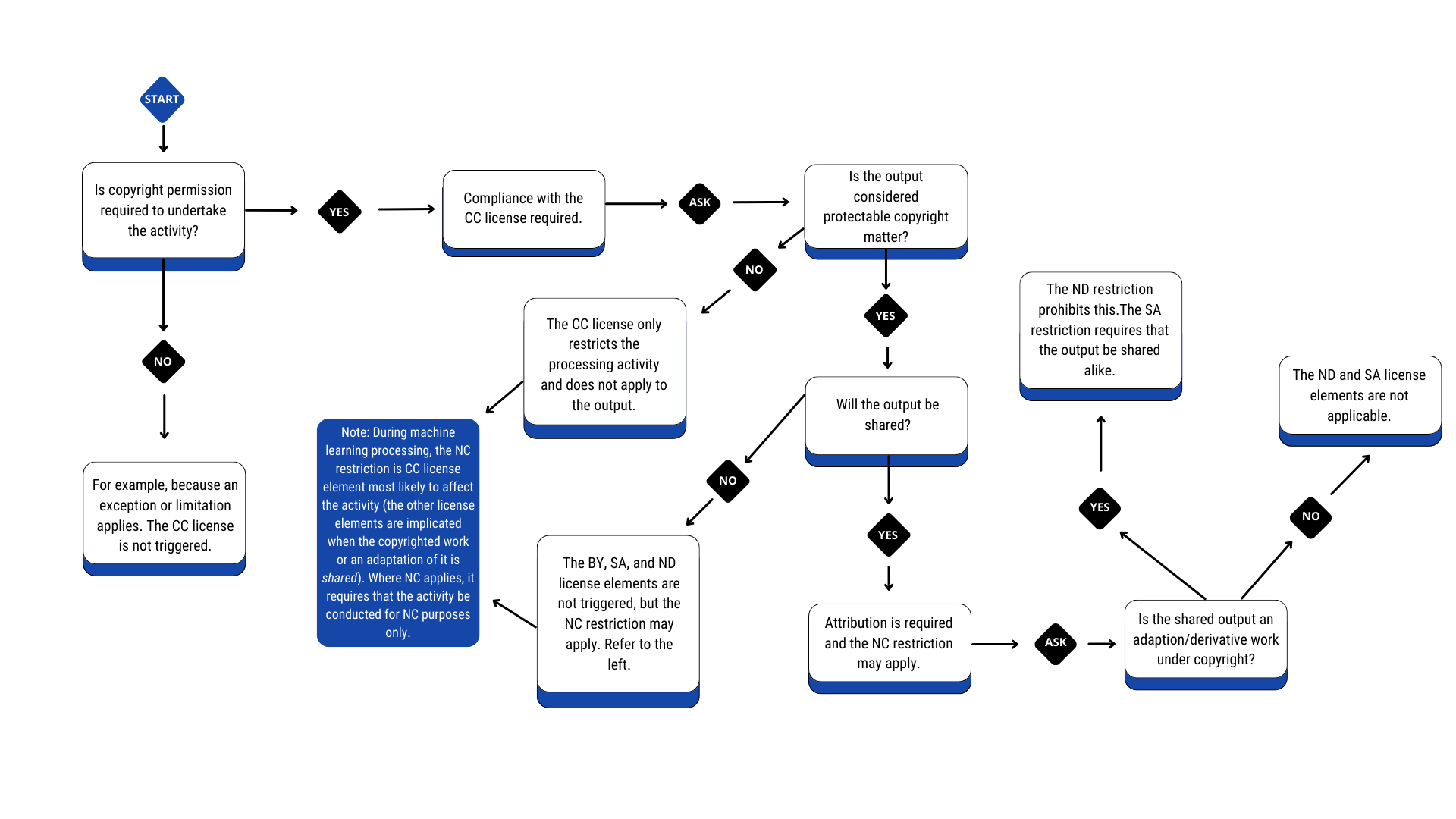
採此份流程圖用於實務分析時,可以再簡化為以下四點指範:
- 若個別的 AI 訓練行為,依法毋須取得原作者著作授權,則亦不需要依循該素材釋出時的 CC授權條款及其相關規範。
- 若個別的 AI 訓練行為,必須取得原作者著作授權為前提,那麼這些授權原則上已被 CC授權條款提供,但是,訓練之後應如何遵守 CC授權條款及其相關規範,要看相關成果與輸出,是否涉及對原作品實質近似的著作表達承襲。
- 當相關成果與輸出,與原作品構成實質近似且為受著作權保護的客體,那麼 CC-BY、CC-SA、CC-NC、CC-ND,都會發揮拘束效力。亦即必須善盡原作品的出處顯名標示義務–CC-BY;而若再有發布,也必須採一樣的授權模式來分享生成物–CC-SA;非商業授權的素材,經 AI 轉化後,亦不得用於商業營利目的–CC-NC;最後,CC-禁止改作 於 4.0 版本後的真實定義,在於闡釋經改作後之作品不得再行被發布或分享,所以說,若是採納到 CC-禁止改作 的素材用於 AI 訓練,相關成果就僅得用於個人或法人內部參考之用,不得再行分享出去–CC-ND。
- 最後,基於 CC-NC 元素在定義上的射程範圍,包含重製素材的前階行為,故若要取用 CC-BY-NC 或 CC-BY-NC-SA 用於 AI 訓練,必須要有將其相關風險等價於私有素材 (proprietary materials) 的理解,亦即就將其視為「權利人保留所有著作權利 (all rights reserved)」之素材,僅有在能援引資料探勘 (TDM) 或各類合理使用之法定抗辯時,方才條件式取用,會是比較務實與低風險的作法。
【社會共識與實務操作仍需逐步磨合與調整】
從訴訟觀察可知,AI 廠商已普遍遍歷整個網路空間擷取訓練資料。未來 AI 訓練素材的發展重點,不再是「取量」,而是「取準」、「取合法」。而根據美國著作權辦公室《著作權與 AI 第三報告(草案)》:https://www.copyright.gov/ai/Copyright-and-Artificial-Intelligence-Part-3-Generative-AI-Training-Report-Pre-Publication-Version.pdf ,若生成式 AI 的輸出侵蝕到原作品市場,極可能構成侵權,不易被認定為合理使用。而合理使用本質上即屬個案審查機制,無法一體適用。
因此,善用 CC 授權與開放資料所提供的合法、正確且具可追溯性的素材來源,是未來生成式 AI 訓練的務實方向。例如:
- EleutherAI 所建立的 Common Pile v0.1 廣泛使用 CC0、CC-BY、CC-BY-SA 授權的資源。
- 法國新創公司 Pleias 與法國文化部、Wikimedia Enterprise 等合作開發的 Common Corpus,亦是取用開放授權資料為原則之多語語料庫。
然而雖然大方向是如此,仍有許多需要透過分享、討論,以調校出最佳實踐方案並建立社會共識的應對之方。例如「採 CC-BY 授權發布的素材,是否即必然得用於生成式 AI 之訓練?」這段話初看沒有什麼問題,誠然採 CC BY 授權發布的素材,只要能勤勉的註引出處來表彰原作當事人之顯名地位,後續相關的應用皆在著作權之授權容許範圍之內,然而,具體落實到實作階段,當前 AI 訓練對素材的採用,不再受限於個、十、百、千、萬篇文章或圖畫,而可能涉及浩繁出處,若是個別文章、圖畫的作者都希望被明確表彰,這在 AI 輸出的應用上,幾乎是不可能被完美實踐的任務與要求。目前 Creative Commons 的呼籲是依循 CC授權法律條款裡原有的「合理標示 (in any reasonable manner based on the medium, means, and context)」機制,來進行處理和應接,亦即當涉及 AI 訓練時,或許將姓名標示的實踐方式,採鏈結方式註解至來源資料集即可,然這樣的情事變通,仍需要持續與公眾和 CC授權的應用者宣導,來統一態度,亦有賴於收納或提供相關素材的中介平台,能逐步和貢獻作品的原作者間建立提供利用上的默契。
此外,Creative Commons 正逐步發展「AI 訓練偏好信號輔助機制 (CC Signals)」,採用偏好信號 (Preference Signals) 內嵌於所釋出素材機器可讀的詮釋資料,以協助創作者表意,其作品得否被用於 AI 訓練用途。目前初步研議設立四種表達偏好,包括「標示姓名、標示姓名+回饋原作者、標示姓名+回饋生態系,以及標示姓名+保持開放」四個可標示選項,亦為一種透過分享、討論,以調校建立社會共識的疏導之方,將於後續專文陸續補充說明。
本文初始發表於 2025 年 7 月 7 日,作者時任 CC Taiwan Chapter Lead 與群牧開源管理顧問有限公司法制顧問。